学了 C++ 的我表示不会 C
前言
在 Linux 上学习 C,更具体来讲,在命令行学习 C 有很多好处,比如说:
- 能了解从写代码到执行这一过程中,计算机到底做了什么事?
- 能了解代码是如何与操作系统,操作系统是如何与硬件沟通的?
总之,对于我这个电子科学的学生来讲,学好 C 比学好 C++ 更加有用。而在 Linux 上学习能帮助我深入理解内部的原理。我决定立个 Flag,在3 个月内学习下面的内容:
- C 语言入门
- 常量、变量和表达式
- 函数
- 分支语句
- 循环语句
- 结构体
- 数组
- 编码风格
- gdb
- 排序与查找
- 栈和队列
- 进程
第 1 章 C 语言入门
编程语言(Programming Language)分为低级语言(Low-level Language)和高级语言(High-level Language)。机器语言(Machine Language)和汇编语言(Assembly Language)属于低级语言,直接用计算机指令编写程序。而C、C++、Java、Python等属于高级语言,用语句(Statement)编写程序,语句是计算机指令的抽象表示。
C语言的语句和低级语言的指令之间不是简单的一一对应关系,需要由编译器(Compiler)来编译(Compile)才能翻译成机器指令。
C语言是可移植的(Portable)或者称为平台无关的(Platform Independent)。不同的计算机体系结构有不同的指令集(Instruction Set),可以识别的机器指令格式是不同的,直接用某种体系结构的汇编或机器指令写出来的程序只能在这种体系结构的计算机上运行,然而各种体系结构的计算机都有各自的C编译器,可以把C程序编译成各种不同体系结构的机器指令,这意味着用C语言写的程序只需稍加修改甚至不用修改就可以在各种不同的计算机上编译运行。
总结一下编译执行的过程,首先你用文本编辑器写一个C程序,然后保存成一个文件,例如program.c(通常C程序的文件名后缀是.c),这称为源代码(Source Code)或源文件,然后运行编译器对它进行编译,编译的过程并不执行程序,而是把源代码全部翻译成机器指令,再加上一些描述信息,生成一个新的文件,例如a.out,这称为可执行文件,可执行文件可以被操作系统加载运行,计算机执行该文件中由编译器生成的指令。
第一个程序
在 vim 中打开一个空白的 main.c 文件,输入:
1 | |
然后保存,在命令行中编译执行:
1 | |
gcc是Linux平台的C编译器,编译后在当前目录下生成可执行文件a.out,直接在命令行输入这个可执行文件的路径就可以执行它。如果你想指定可执行文件的名字,可以用:
1 | |
当然,建议显示所有警告信息,用下面这条命令:
1 | |
第 2 章 常量、变量和表达式
常量(Constant)是程序中最基本的元素,有字符(Character)常量、整数(Integer)常量、浮点数(Floating Point)常量和枚举常量。
字符常量中有一类特殊的字符叫转义字符(Escape Sequence),比如:
| 转义字符 | 作用 |
|---|---|
| \’ | 单引号’(Single Quote或Apostrophe) |
| \” | 双引号” |
| \? | 问号?(Question Mark) |
| \ | 反斜线\(Backslash) |
| \a | 响铃(Alert或Bell) |
| \b | 退格(Backspace) |
| \n | 换行(Line Feed) |
| \t | 水平制表符(Horizontal Tab) |
(这部分内容和 C++ 差不多,略过)
第 3 章 函数
数学函数
通过 math.h 库可以使用 sin、ln(在库中是 log) 等数学函数。
顺便说一句,C标准主要由两部分组成,一部分描述C的语法,另一部分描述C标准库。C标准库定义了一组标准头文件,每个头文件中包含一些相关的函数、变量、类型声明和宏定义。要在一个平台上支持C语言,不仅要实现C编译器,还要实现C标准库,这样的实现才算符合C标准。不符合C标准的实现也是存在的,例如很多单片机的C语言开发工具中只有C编译器而没有完整的C标准库。在Linux平台上最广泛使用的C函数库是glibc。
自定义函数
一个函数定义包括这么几部分:
1 | |
注意几点:
- 有的书上写成:
int main(){},甚至main(){},这是Old Style C的风格。这种宽松的规定使编译器无法检查程序中可能存在的Bug,增加了调试难度,不幸的是现在的C标准为了兼容旧的代码仍然保留了这种语法,但我们绝不应该继续使用这种语法。 - 其实操作系统在调用
main函数时是传参数的,main函数最标准的形式应该是int main(int argc, char *argv[])
除函数体之外的部分叫函数的函数原型。如果我们只写了函数原型没写函数体,就是一个函数声明。编译器在翻译代码的过程中,只有见到函数原型(不管带不带函数体)之后才知道这个函数的名字、参数类型和返回值,这样碰到函数调用时才知道怎么生成相应的指令,所以函数原型必须出现在函数调用之前,这也是遵循“先声明后使用”的原则。
由于有Old Style C语法的存在,并非所有函数声明都包含完整的函数原型,有些声明并没有明确指出参数类型和个数,如果在这样的声明之后调用函数,编译器不知道参数的类型和个数,就不会做语法检查,所以很容易引入Bug。
如果在调用函数之前没有声明,编译器生成函数的隐式声明(Implicit Declaration),默认函数参数为 void,返回值为 int。如果后面函数原型不符,就会出错。(这个在 Arduino 中写程序时遇到过)
形参和实参
形参相当于函数中定义的变量,调用函数传递参数的过程相当于定义形参变量并且用实参的值来初始化。
全局变量、局部变量和作用域
函数中定义的变量称为局部变量(Local Variable),局部变量的特点是:
- 一个函数中定义的变量不能被另一个函数使用;
- 每次调用函数时局部变量都表示不同的存储空间。局部变量在每次函数调用时分配存储空间,在每次函数返回时释放存储空间。
与局部变量相对的是全局变量(Global Variable),全局变量定义在所有的函数体之外,它们在程序开始运行时分配存储空间,在程序结束时释放存储空间,在任何函数中都可以访问全局变量。
如果在函数中定义了与全局变量同名的变量,那么在函数体内全局变量就会被局部变量覆盖掉。
局部变量可以用类型相符的任意表达式来初始化,而全局变量只能用常量表达式(Constant Expression)初始化。
return语句
在有返回值的函数中,return 语句的作用是提供整个函数的返回值,并结束当前函数返回到调用它的地方。在没有返回值的函数中也可以使用 return 语句,例如当检查到一个错误时提前结束当前函数的执行并返回。
递归
有点玄学意味在里面,能让代码短且装逼,不过有时候如果你能不用递归用循环写,那才是真的强(比如遍历)
第 4 章 分支语句
if、if/else 语句咱就不多说了。在此只说一下 switch 的几个要点:
case后面跟表达式的必须是整型常量表达式,这个值和全局变量的初始值一样必须在编译时计算出来。- 进入
case后如果没有遇到break语句就会一直往下执行,后面其它case或default分支的语句也会被执行到,直到遇到break,或者执行到整个switch语句块的末尾。
第 5 章 循环语句
-
while:1
2
3while (condition){ } -
do/while:1
2
3do{ }while(condition); #注意分号 -
for:1
2
3for(expression1;condition;expression2){ } -
goto:1
2
3
4
5
6
7
8for (...) for (...) { ... if (出现错误条件) goto error; } error: 出错处理;这里的
error:叫做标号(Label),任何语句前面都可以加若干个标号,每个标号的命名也要遵循标识符的命名规则。goto语句过于强大了,从程序中的任何地方都可以无条件跳转到任何其它地方,只要在那个地方定义一个标号就行,唯一的限制是goto只能跳转到同一个函数中的某个标号处,而不能跳到别的函数中。(C标准库函数setjmp和longjmp配合起来可以实现函数间的跳转,但只能从被调用的函数跳回到它的直接或间接调用者(同时从栈空间弹出一个或多个栈帧),而不能从一个函数跳转到另一个和它毫不相干的函数中。)
第 6 章 结构体
在编程语言中,最基本的、不可再分的数据类型称为基本类型(Primitive Type),例如整型、浮点型;根据语法规则由基本类型组合而成的类型称为复合类型(Compound Type),例如字符串是由很多字符组成的。有些场合下要把复合类型当作一个整体来用,而另外一些场合下需要分解组成这个复合类型的各种基本类型,复合类型的这种两面性为数据抽象(Data Abstraction)奠定了基础。[SICP]指出,在学习一门编程语言时要特别注意以下三个方面:
- 这门语言提供了哪些Primitive,比如基本类型,比如基本运算符、表达式和语句。
- 这门语言提供了哪些组合规则,比如基本类型如何组成复合类型,比如简单的表达式和语句如何组成复杂的表达式和语句。
- 这门语言提供了哪些抽象机制,包括数据抽象和过程抽象(Procedure Abstraction)。
结构体的基本
结构体定义:
1 | |
结构体用于定义变量:
1 | |
结构体变量在定义时初始化:
1 | |
Initializer中的数据依次赋给结构体的各成员。如果Initializer中的数据比结构体的成员多,编译器会报错,但如果只是末尾多个逗号则不算错。如果Initializer中的数据比结构体的成员少,未指定的成员将用0来初始化,就像未初始化的全局变量一样。
访问结构体:
1 | |
第 30 章 进程
创建新进程 fork函数
1 | |
fork() 调用失败则返回-1,调用成功则:
- 在子进程中返回0,子进程仍可以调用
getpid函数得到自己的进程id,也可以调用getppid函数得到父进程的 id。 - 在父进程中返回子进程的 id,父进程用
getpid可以得到自己的进程id,然而要想得到子进程的id,只有将fork的返回值记录下来,别无它法。
运行程序 exec函数
用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。调用exec并不创建新进程,所以调用exec前后该进程的id并未改变。
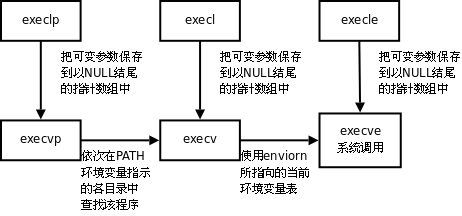
有六种以exec开头的函数,统称exec函数:
1 | |
这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回,如果调用出错则返回 -1,所以 exec 函数只有出错的返回值而没有成功的返回值。
下面解释各个函数的区别:
- 不带字母 p(表示path)的
exec函数第一个参数必须是程序的相对路径或绝对路径,例如"/bin/ls"或"./a.out", 而不能是"ls"或"a.out"。 - 对于带字母 p 的函数:
- 如果参数中包含/,则将其视为路径名。
- 否则视为不带路径的程序名,在
PATH环境变量的目录列表中搜索这个程序。 - 带有字母 l(表示list)的
exec函数要求将新程序的每个命令行参数都当作一个参数传给它 ,命令行参数的个数是可变的,最后一个可变参数应该是NULL,起 sentinel 的作用。 - 带有字母 v(表示vector)的函数,则应该先构造一个指向各参数的指针数组,然后将该数组的首地址当作参数传给它,数组中的最后一个指针也应该是
NULL,就像main函数的argv参数或者环境变量表一样。 - 对于以e(表示environment)结尾的
exec函数,可以把一份新的环境变量表传给它,其他exec函数仍使用当前的环境变量表执行新程序。
事实上,只有execve是真正的系统调用,其它五个函数最终都调用execve , 这些函数之间的关系如下图所示。:
清除子进程 wait和waitpid函数
一个进程在终止时会关闭所有文件描述符,释放在用户空间分配的内存,但它的 PCB 还保留着,内核在其中保存了一些信息:如果是正常终止则保存着退出状态,如果是异常终止则保存着导致该进程终止的信号是哪个。这个进程的父进程可以调用 wait 或 waitpid 获取这些信息,然后彻底清除掉这个进程。 比如: 一个进程的退出状态可以在Shell中用特殊变量 $? 查看,因为Shell是它的父进程,当它终止时Shell调用 wait 或 waitpid 得到它的退出状态同时彻底清除掉这个进程。